Going deep into backpropagation
[[toc]]
Backpropagation
I have written this description about the intrinsics of backpropagation to get a quick and clear insight into the idea and the mathematics of backpropagation in a level which a first year CS master student should understand. I myself use this for a quick reminder, so maybe the best purpose for this should be recap. At least the mathematics should be generally correct
Some references
- https://www.coursera.org/learn/machine-learning/supplement/pjdBA/backpropagation-algorithm
- https://mattmazur.com/2015/03/17/a-step-by-step-backpropagation-example/
Why it is important to know this
- https://medium.com/@karpathy/yes-you-should-understand-backprop-e2f06eab496b
Algorithm
Definitionsss
- K = number of output units
- L = number of layers in network
- number of units in layer l
- m = number of training examples
- E - another symbol for cost function J
- - regularization term
- - this is used for cumuating the gradietns calculated on every training example for every theta
- D - final gradient after one iteration of backpropagation.
Steps
Assumptions about Dimensions
- We currently do backpropagation on every training example separately
FORWARD PROPAGATION DIMENSION SPECIFICATION
If network has units in layer j and units in layer j+1, then will have rows and columns. (The +1 for columns comes from bias nodes).
This result in (and also ) being a vector with dimensions X
BACKPROPAGATION DIMENSIONS SPECIFICATION
Continuing with the last example, has also X dimensions. Hint to backpropagation part later on:
Algorithm
Initialize
REPEAT FOR
- Perform Forward Propagation. This can be done using the training matrix as well. Result is going be in the size of (m * K ).
Example of forward propagation

- Calculate the cost
- Definitions
- - Hypothesis function parameters
- Hypothesis function
- i-th training data
- Definitions
- Calculate derivatives of Cost Function according to every
- Calculate derivatives for every theta
- Add cumulatively to
or in vectorial form
END LOOP
- final form of derivative after this training step
- Update if j no equal 0 <- add derivative of regularization
- Update j = 0 <- no regularization for bias term
Elaboration about Derivatives
3. Step - Calculating
Calculating
It is important to note that is pretty much for all z.
Calculating is different from calculating …
- You have to calculate and
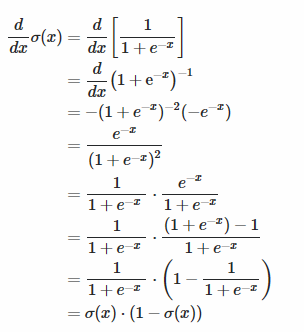
Here is the derivation for
Calculating GENERAL CASE
Reminder: In each level l derivative we can have multiple , like we have multiple
Calculation is done somewhat recursively. For every smaller level we need to use in our calculation of the derivative because of the chain derivative rule: . If, inside the formula we go further from the output in layer L towards the input in layer 1, we need to always take functions in between under consideration.
In other words
Here that part in bold stands for the part thats being added.
This translates to
Where each part stands for
-
In each row consists of derivatives for 1 single i-th for all . For each we have multiple and column j in consists of derivatives for
-
in i-th row ańd j-th column we have . The multiplication is going to have l num_layers X 1 dimensions.
- This rule is somewhat more interesting, because it applies a somewhat complicated concept where 1 variable in a function affects the end result through multiple other functions. E.g Such a function, when taking a derivative is solved by just summing up all the derivatives. This is somewhat intuitive but I wont go too deep into it
- Explanation in Estonian of this rule
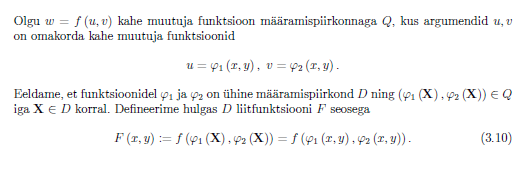
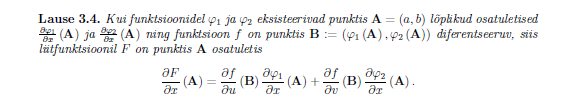
4. Step - Calculating
Reminder
- 1 scalar has effect only on 1 z
This in regular derivative form translates to
This translates in vectorial form to
results in i x j matrix, like
Gradient Checking
https://www.coursera.org/learn/machine-learning/supplement/fqeMw/gradient-checking
- Do it for all the -s and matrices
- For 1 matrix this looks like this.
thetaPlus=zeros(theta)
gradApprox=zeros(theta)
epsilon = 1e-4;
for i = 1:n,
thetaPlus = theta;
thetaPlus(i) += epsilon;
thetaMinus = theta;
thetaMinus(i) -= epsilon;
gradApprox(i) = (J(thetaPlus) - J(thetaMinus))/(2*epsilon)
end;